The National Ecological Observatory Network has invested in high-resolution airborne imaging of their field sites.
Elevation models generated from LiDAR can be used to map the topography and vegetation structure at the sites.
This data gets really powerful when you can compare ecological processes across
sites.
Download the elevation models for the Harvard Forest (HARV) and San Joaquin Experimental Range (SJER)
and the plot locations for each of these sites.
Often, plots within a site are used as representative samples of the larger site
and act as reference areas to obtain more detailed information and ensure
accuracy of satellite imagery (i.e., ground truth).
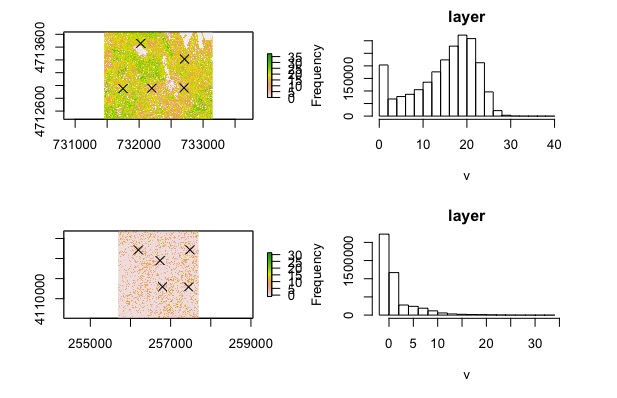
Create two Canopy Height Models using simple raster math (chm = dsm - dtm), one for the HARV site (which was done during the lecture) and another for the SJER site.
Create plots and histograms of canopy heights for both of the sites on a single panel. To do so, type in the following line first to set up the panel: par(mfrow = c(2, 2), mar = c(5, 4, 2, 2)). This specifies that there will be four figures on the same panel, and their margins. In the following lines, create the four plots using plot() and hist(). If you run these five lines together, they should create a 4-figured panel.
Add corresponding points from plot_locations folder to each site plot. Don’t forget to use the add = TRUE argument to add one plot on top of another. If points don’t show up, compare the crs of the canopy height model and the plot locations.
Create a single dataframe with two columns, one of the maximum canopy heights for each point at the HARV site and one for the SJER points’ maximum canopy heights. When extracting the canopy height values, use a buffer of 10.

{kind=link}